
Reference paper: Situated Human-Robot Collaboration: predicting intent from grounded natural language [PDF] [BIB]
Authors: Jake Brawer, Alessandro Roncone, Olivier Mangin, Sarah Widder,and Brian Scassellati
Submission: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS2018), Madrid, Spain, October 1-5, 2018
Research in human teamwork shows that a key element of fluid and fluent interactions is the interpretation of implicit verbal and non-verbal cues in context. This poses an issue to robotic platforms, as they work best when controlled through explicit commands that employ structured, unequivocal representations of the external world and their human partners. In this work, we present a framework for effectively grounding situated and naturalistic speech to action selection during human-robot collaborative activities.
Video summary of the proposed work.
Method
We propose a flexible approach for incrementally deriving a model of the desired robot’s behavior from utterances and context. This is accomplished by maintaining and updating distinct models of the speech and the context in relation with robot actions, the outputs of which are combined for action selection. For a given utterance and the associated context, each model yields a probability distribution over actions (cf. Fig 1).
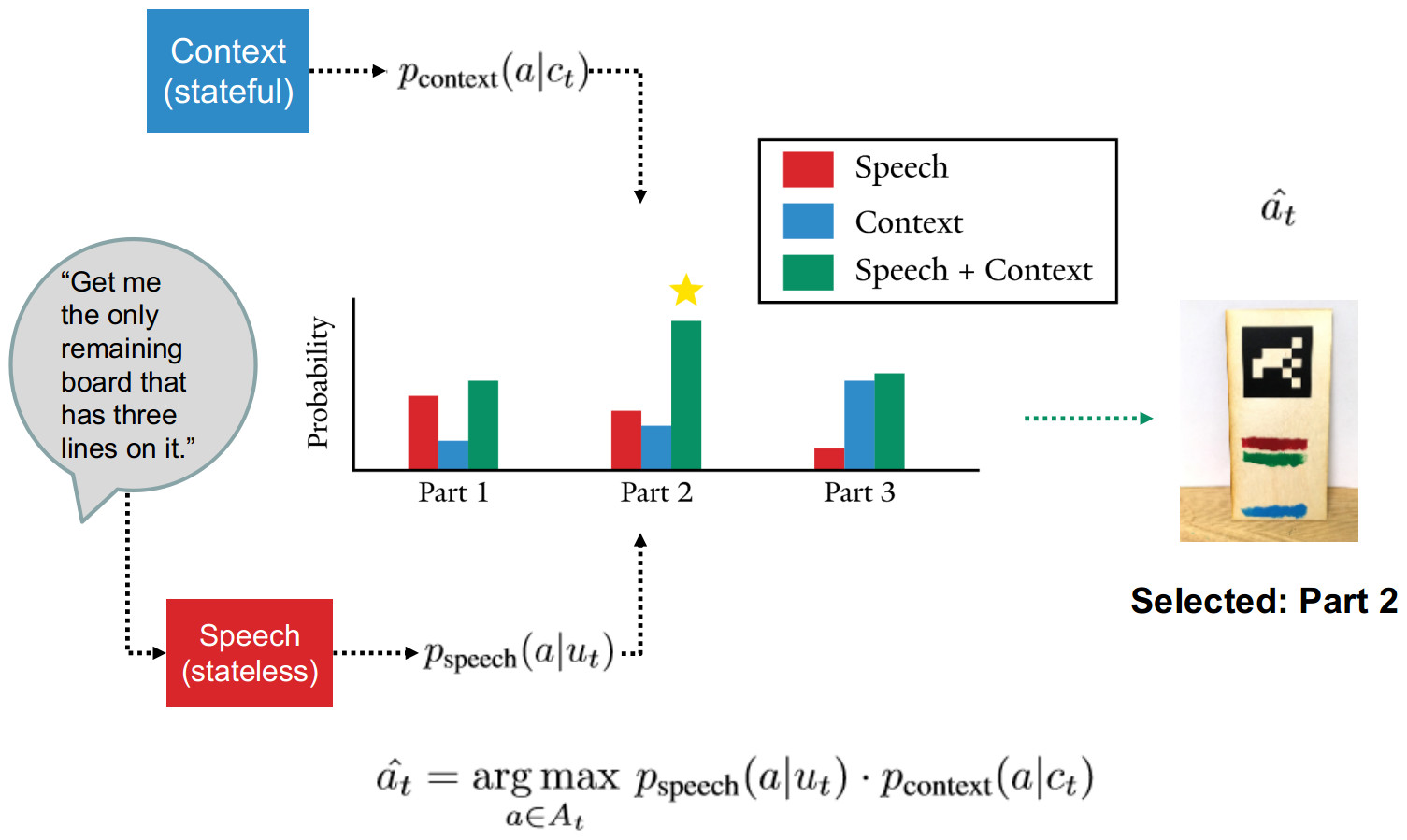
Figure 1. Software architecture.
Here context refers to both the presence of objects in the workspace but also the action history of the robot-the sequence of successful actions taken up until the current moment. For the purpose of this experiment we introduce a simple context model that records counts of actions taken in any context. We use a speech model based on logistic regression. Each utterance command is converted by the speech-to-text system and then represented as a bag of n-grams of size one and two. These embeddings are then passed to the logistic regression which attempts to classify the utterance to a particular robot action.
Experimental Results
We evaluate the efficacy of the system on a collaborative construction task with an autonomous robot and human participants. We first demonstrate that our system is capable of acquiring and deploying new task representations from limited and naturalistic data sets, and without any prior domain knowledge of language or the task itself. Finally, we show that our system is capable of significantly improving performance on an unfamiliar task after a one-shot exposure. This suggests that the system develops approximate yet adaptable representations of tasks which can be generated quickly, but also deviated from should it be required.